
From Machine Learning to MLOps: The Next Step in Enterprise AI
-
 Sanplex Content
Sanplex Content -
 2026-03-02 11:50:00
2026-03-02 11:50:00 -
 303
303

Machine learning is no longer confined to research teams or innovation labs. It is increasingly used in real business scenarios and is becoming a standard part of modern software delivery. As adoption grows, the conversation is shifting. The question is no longer what machine learning can do, but how organisations can deliver machine learning projects reliably and at scale.
That is where the challenge begins.
Compared with conventional software such as web platforms or mobile apps, machine learning systems are much harder to develop, deploy, operate, and continuously improve. The good news is that the industry has gradually built a more structured way to manage this complexity. This is exactly why MLOps has become such an important topic.
1. Why does machine learning need engineering?
Data has become one of the most valuable assets an enterprise owns, and more companies want to become truly data-driven. Under the pressure of digital transformation, organisations across industries are introducing machine learning into business workflows in order to improve decision-making, automation, and customer experience.
But creating value from machine learning in a production environment is still far from straightforward.
In many enterprises today, machine learning systems still exist as isolated subsystems rather than as a fully integrated part of the core business platform. People often imagine a future in which machine learning adapts seamlessly to changing business scenarios and works naturally with enterprise applications. In reality, there is still a significant gap between that vision and day-to-day implementation. In many cases, machine learning remains an external capability connected to business processes rather than embedded deeply within them.
Another common misconception is that machine learning is mostly about model code. It is not. In real-world applications, whether in autonomous driving, credit risk control, or image recognition, the model itself is only a small part of the solution. The majority of the work lies in engineering.
Engineers must take models created by data scientists and make them work in real software environments. That means integrating them into products, ensuring they can handle changing data, and maintaining their performance over time. A model that performs well in a controlled training environment may quickly degrade in production when data patterns shift or operating conditions change.
This is why machine learning delivery requires a cross-functional team. A successful setup often involves data scientists or ML engineers, DevOps engineers, and data engineers working together. Their responsibilities go far beyond training a model. They also need to monitor model quality, retrain models when necessary, evaluate new implementations, and keep the entire system stable in production.
To reduce the friction and manual effort involved in this work, organisations have begun using MLOps practices to build CI/CD-style workflows for machine learning. These workflows help teams test, build, retrain, and deploy models more efficiently, while closing the gap between experimental model development and operational delivery.
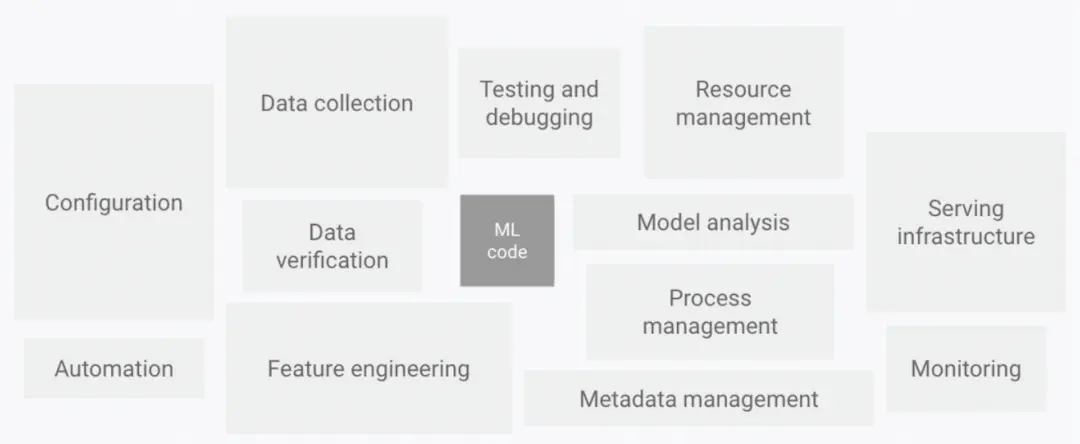
2. Why is machine learning so hard to engineer?
In traditional software development, engineering is closely tied to collaboration, quality control, and predictability. A well-engineered project allows teams to manage scope, schedule, and cost in a controlled way. It depends on shared processes rather than individual heroics.
When engineering is weak, two patterns usually appear.
The first is overdependence on individuals. If outcomes rely mainly on one person’s personal skill, with limited collaboration or handover capability, the work is not strongly engineered. Even in application development, a team that depends too heavily on individual contribution rather than collective execution often struggles to scale.
The second pattern is exploration-heavy work. Engineering works best when the team broadly understands the target, the process, and the steps required to get there. Exploratory work is different. In exploratory work, teams do not fully know what path will succeed, what sequence of actions will work best, or even whether the intended outcome can be achieved at all. That kind of uncertainty naturally resists standardisation.
Machine learning contains both of these characteristics.
It relies heavily on the expertise and judgement of data scientists, and it also involves a large amount of trial and error. Teams constantly test hypotheses, explore datasets, tune hyperparameters, compare architectures, and adjust training strategies. Even though deep learning has reduced some manual feature engineering work, success still depends heavily on experience, experimentation, and iteration.
That is exactly why machine learning has historically been difficult to industrialise. It is not just software development with a different toolkit. It is a discipline that sits between research and engineering, and that makes structured delivery much harder.
3. Why does machine learning engineering require a new toolchain?
Machine learning projects differ from traditional software projects in a fundamental way: code is only part of the deliverable. Data and models are equally critical, and in many cases even more important.
In conventional software engineering, code and data are often treated separately. In machine learning, that distinction breaks down. A model’s behaviour is shaped not only by the codebase but also by the training data, validation data, feature pipelines, and model artefacts. As a result, managing machine learning in production requires a broader engineering system.
Over the past several years, the industry has made meaningful progress in turning machine learning from a highly individual and experimental activity into something more collaborative and repeatable. That transition is important because once machine learning becomes part of a team workflow, it can begin to fit into the wider enterprise technology ecosystem.
The first step in that transition is building a collaborative development process. Teams need version control, shared artefacts, traceability, and clear handover mechanisms so that work does not remain locked in one person’s notebook or local environment.
The second step is connecting development and production more closely. In machine learning, teams must be able to move from experimentation to deployment in a controlled way, while also handling data updates, model refreshes, monitoring, and maintenance in production.
This is where traditional software tooling starts to fall short.
In standard software development, version control works well because code changes are relatively small, text-based, and easy to compare line by line. In machine learning, versioning must go beyond source code. Teams also need to manage training datasets, model files, parameters, and experiment histories. Data may include images, audio, logs, or structured records, and its evolution is often continuous rather than neatly segmented.
That means the concept of a version is different in machine learning. Code versions are usually tied to specific text changes. Data versions may reflect time windows, data snapshots, feature sets, or training inputs collected across a period. Because of this difference, machine learning engineering needs tools designed specifically for data-centric workflows, not just conventional software pipelines.
4. Why MLOps is not simply DevOps for machine learning
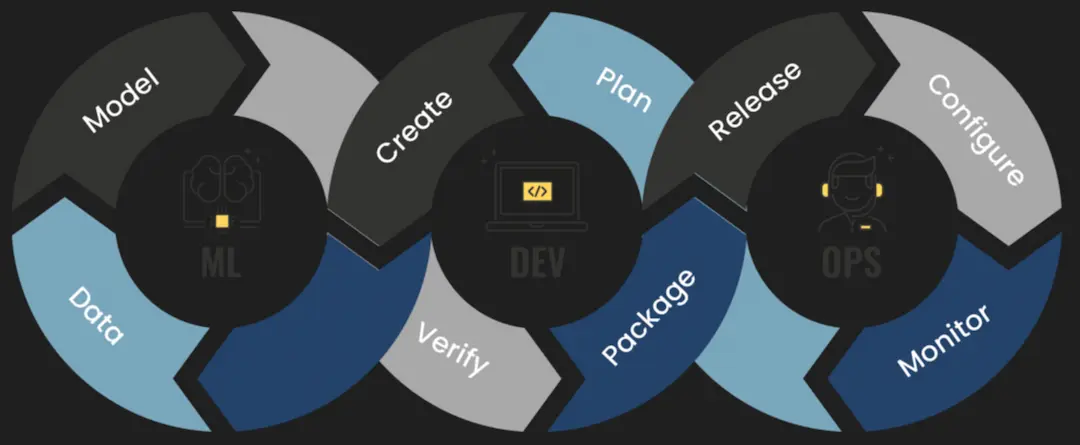
The rise of tools such as DVC helped the industry think more clearly about machine learning workflows. Teams began to recognise that writing model code is only one stage in the process. The larger challenge is making the full workflow reproducible and production-ready, including version control, model serving, deployment, integration testing, experiment tracking, and retraining.
Once these pieces are in place, they still need to be connected through an end-to-end operational process. That is the role MLOps plays. It brings continuity and structure to machine learning delivery so that teams can move from isolated experiments to repeatable production systems.
MLOps is often described as a combination of DevOps, data science, and software engineering. That description is useful, but it can also be misleading if taken too literally. MLOps is not just DevOps applied to models.
In traditional software delivery, DevOps focuses on packaging software, deploying it reliably, and maintaining the infrastructure that runs it. Historically, development teams wrote the software and operations teams managed the environments. As cloud platforms matured, developers gained more control over infrastructure, which helped give rise to DevOps. In that world, new releases are typically treated as updated software packages deployed onto managed systems.
Machine learning operates differently.
A machine learning system is not only code running on infrastructure. It also includes data pipelines, model training, validation logic, parameter tuning, and continuous adaptation to real-world inputs. Data scientists may build models in notebooks or specialised tools, but those environments often differ significantly from the production environment where the model must actually run.
Once a model is deployed, the work is still not finished. Real-world data changes. Model performance drifts. Teams may need to collect new data, retrain the model, adjust parameters, and redeploy repeatedly. The main challenge MLOps addresses is not just deployment, but the ongoing operational loop that connects training, validation, release, monitoring, and improvement.
This also means that the people who design a model and the people responsible for operating it in production may not be the same. MLOps helps bridge that gap by creating a structured process that ties everyone’s work together.
Compared with DevOps, MLOps is less focused on the machine itself and more focused on how the model evolves: how parameters are managed, how model behaviour is monitored, whether the architecture needs to be updated, and when retraining should occur.
The two disciplines overlap in their concern for reliable production operations, but their engineering focus is fundamentally different.
5. MLOps is only the beginning
Machine learning engineering is still in its early stages.
What is changing now is that organisations are moving beyond conversations about model architectures and feature engineering alone. They are starting to pay much more attention to how machine learning moves from experimentation into production, and how teams can establish shared processes around that transition.
That is why MLOps matters.
It represents an important shift in how enterprises approach AI. Instead of treating machine learning as a purely experimental domain, companies are beginning to treat it as an engineering discipline that can be structured, automated, measured, and improved.
This field is still evolving quickly. The tools, workflows, and best practices are far from final. But that is exactly what makes this moment so important. MLOps is not the end state of enterprise AI. It is the foundation that makes scalable, production-grade AI possible.
As organisations continue to mature their engineering practices, machine learning will become less dependent on isolated expertise and more integrated into the broader software delivery lifecycle. That is the real next starting point for AI in the enterprise.


